A Comprehensive Approach to Atomic Commit In Sqlite Database

Published: April 5th, 2016 • 6 Min Read
In our last blog we discuss about Sqlite Python, this time we will cover an interesting and a least known fact of Sqlite and Sqlite3 that is Atomic commit. Atomic commit stand out as one of the most important characteristic of transactional databases. The term ‘Atomic Commit’ implies that all the changes done to a database are either done entirely or are not done at all. In Sqlite, Atomic commit makes it appear that all the write transactions to different sections of a particular database are done simultaneously and in an instant, which is practically impossible. Therefore Sqlite just creates an illusion that the changes are being made simultaneously. In this piece of writing we will only discuss about atomic commit, when Sqlite is working in a rollback mode and not in a write-ahead mode.
Atomic Commit for a Single File
Sqlite executes a number of operations in order to perform Atomic Commit for single file databases.
1. Primary Stage
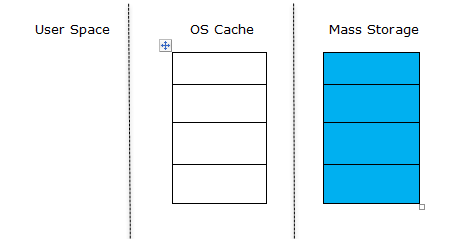
When a database is initially accessed, the entire data is stored in the hard drive or the mass storage. No data resides on the operating system cache memory and the user space is also empty as the database has just been opened and no data has been read yet.
 2. Obtaining Read Lock
2. Obtaining Read Lock
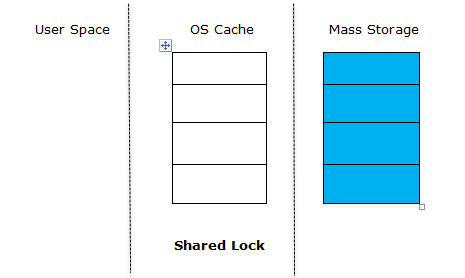
Before writing into the database, Sqlite must read the already stored data. In order to read the data, firstly Shared Lock needs to be acquired for the database. The shared lock enables two or more processes to read from the same database but does not allow them to write anything while we are reading the database. This is done to avoid reading incomplete data by us.
 3. Reading The Database
3. Reading The Database
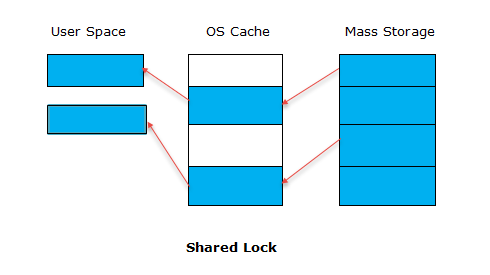
The next step is to read the database from the mass storage device. Since no data is currently residing on the OS cache, therefore the data will first be passed to OS cache and then will be delivered to the user space. After sometime, the entire information will be present on the cache and therefore information will only be passed to user space.
 4. Acquiring Reserved Lock
4. Acquiring Reserved Lock
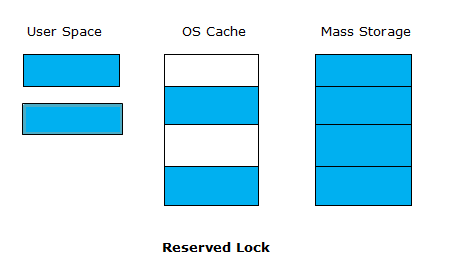
Before writing into the database, it is necessary to acquire ‘Reserved lock’ on the database. The reserved lock enables the database to be read by the entire database but no write changes can be made to it by others. Only the process possessing the Reserved right will be able to write in the database.
 5. Creation Of Rollback Journal
5. Creation Of Rollback Journal
Before making any permanent changes into the database, SQLite firstly creates a Rollback journal to store the original status of the database. This is done to make sure that any mishap while making changes does not delete the database. In case the data is deleted, the roll\back journal can be used to get the database back to its original state. Also the rollback journal contains a header that contains the actual size of the database, which in case of mishap will help know the changes done to the database.
6. Making Database Changes
Once the original content is saved in the rollback journal, changes can be made in the user memory pages. Every database holds a private copy of the user space and therefore the changes that are made will only be visible to the database that is making the changes.
7. Writing The Rollback Journal To Mass Storage
Now, the content of the rollback general are meant to be written to a non-volatile storage device. This is done in order to keep the data safe in case of sudden power disruption
8. Acquiring Exclusive Lock
Exclusive lock is acquired in two steps. In the first step, a pending lock is acquired which does not permit more processes, other than the existing ones, to read from the database. The pending lock is then changed to exclusive locks, which disables all the processes to read from the database.
9. Writing Changes To OS Cache
Once the exclusive lock is acquired, Sqlite writes the changes to the OS cache and do not get written to the mass storage.
10. Making Changes To Mass Storage
The changes made to the database, are then written to the mass database. This is a very slow process and will consume majority of time of the overall transaction.
11. Rollback Deletion
After the changes are being made safely to the mass storage, the rollback journal file is deleted. It is at this instant, that a transaction gets fully committed.
12. Releasing Exclusive Lock
The last step in the process is to release the exclusive lock on the database. This will allow other processes to continue their work with the database.
Atomic Commit for Multiple Files
Maintaining atomic commit for multiple files is more difficult than for a single file. Read on to know more.
1. Different Rollback Journal Per Database
For multiple databases that are involved in a transaction, there exists a separate reserved lock for each database. Before making any changes, the original content of all the databases have been written to the rollback journal and changes been made to the database are not yet written to the mass storage.
2. Creation Of Master Journal
The next step is the creation of the master journal. This master journal unlike rollback journal does not consist of the original data, but stores the name of the paths of rollback journals of each database taking part in the transaction. The data stored in the master journal is then flushed to the mass storage.
3. Writing In Rollback Journal Headers
Once the master journal is created, its path name is updated in the header section of the rollback journals of each database. After updating the headers, the changes are made to the mass storage or disk.
4. Writing In Database Files
After acquiring exclusive locks on all the databases, the changes are made in them. Afterwards, all the recent changes are flushed to the mass storage.
5. Deletion Of Master Journal File
Now the master journal file is deleted and it is at this instant that multiple file transactions take place. In case of power failure, the transactions will not roll back.
6. Deletion Of Rollback Journals
The final step is to delete all the individual rollback journal files of the multiple files and to remove all the exclusive locks acquired on the databases. Each rollback journal is deleted one by one and then succeeded by removal of locks.
After reading the above section, we believe that you might have gained an idea of the atomic commit of both single and multiple files in Sqlite. You can also practically analysis all these file and structure by using Sqlite Database Browser.
